

近日,我院于帅老师课题组在音乐信息检索领域的研究工作被CCF A类会议AAAI 2024 接收,这也是该课题组在音乐信息领域取得的系列重要进展之一。到目前为止,课题组已经在歌声旋律提取等音乐信息检索核心问题取得了重要进展,发表了多篇CCF A/B类会议论文。
(一)为了解决歌声旋律提取中的标注数据稀缺和模型泛化性差的问题,我们提出了一个基于多任务对比学习的半监督歌声旋律提取模型。

为了克服标注音乐数据稀缺的问题,我们提出了一种自洽正则化(self-consistency regularization, SCR)的方法,我们对无标签的音乐原始数据进行4种转换,然后将这些信号用于模型的预测。我们不但要求模型能够一致的预测出旋律线的位置,还要求模型能够识别出输入进来的音乐信号做了何种转换。为了克服不同音乐流派在提取歌声旋律时泛化性能较差的问题,我们提出了一种领域自适应的方法,让模型能够学习领域无关的特征用于歌声旋律提取。最后,我们将上述模块的损失函数一起进行优化,进行多任务学习。我们提出的模型在4个公开数据集上均取得了state-of-the-art的效果,有效解决了歌声旋律提取中标注数据稀缺、泛化能力差的问题。
该项工作发表于AAAI 2024(CCF A),我院于帅老师为第一作者,太阳集团tcy8722我院为第一单位。
(二)歌声旋律提取是音乐信息检索领域的核心问题。歌声旋律提取模型在实际应用中,经常被部署在手机等移动设备上。随着vision transformer在计算机视觉领域取得了巨大的成功,研究人员提出将vision transformer应用在歌声旋律提取任务上。但是vision transformer巨大的计算量和参数量,对模型在移动设备上的部署带来了困难。
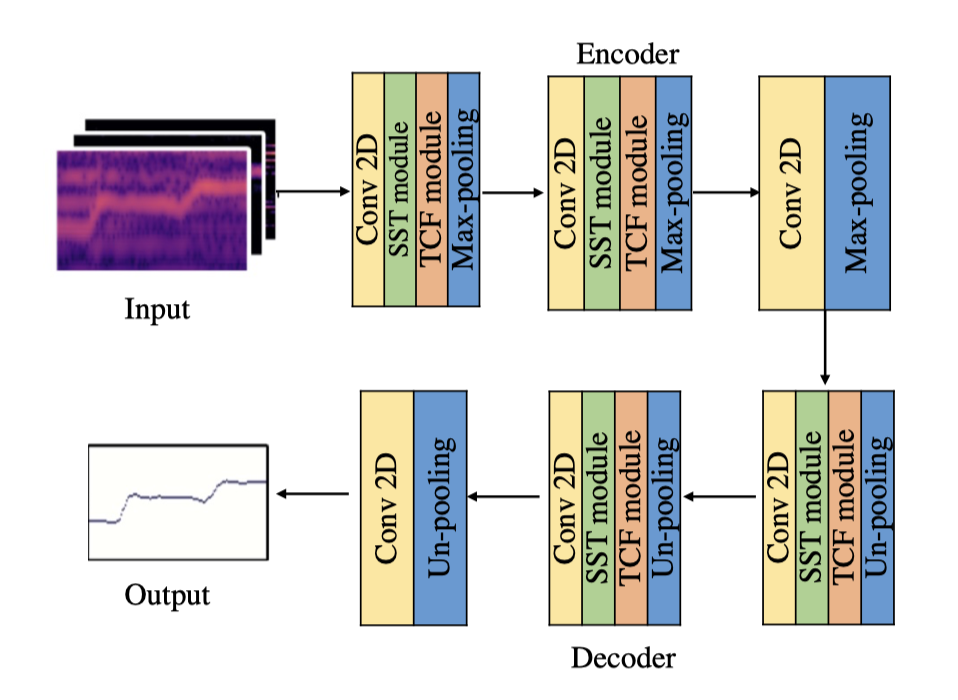
为了克服vision transformer在移动设备部署困难的问题,我们提出了一种可扩展的稀疏transformer模型用于歌声旋律提取。首先,我们提出了一个稀疏的transformer模型用于歌声旋律提取,这个模型只需要计算当前帧所在行和列在频谱上的关联,极大地降低了计算量和参数量。然后,我们又提出了一个可扩展的稀疏transformer模型,这个模型可以在那些算力稍强的移动设备进行部署,它在稀疏transformer模型的基础上进一步计算当前帧相邻帧/频带之间的相关性。最后,我们将这个可扩展的稀疏transformer模型与一个轻量化的CNN 模型结合在一起,以弥补transformer训练收敛慢的缺点。我们提出的模型在3个公开数据上均取得了state-of-the-art效果。有效地解决了歌声旋律提取模型在移动设备上的部署问题。
该项工作发表于ICASSP 2024(CCF B),我院于帅老师为第一作者,2023级研究生刘骏为学生第一作者,太阳集团tcy8722我院为第一单位。