

近日,我院常姗老师课题组在联邦学习激励机制领域的研究工作被CCF A类会议INFOCOM 2024接收,这也是该课题组在联邦学习激励机制领域取得的系列重要进展之一。到目前为止,课题组已经在联邦学习激励机制领域取得了重要进展,发表了多篇CCF A/B类会议论文。
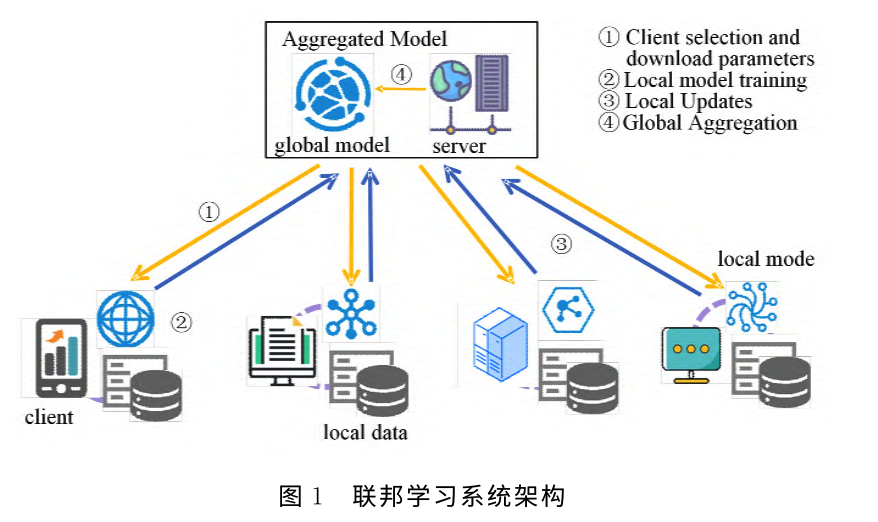
在分布式机器学习框架联邦学习中,参与者使用他们的本地数据(隐私敏感)来训练本地局部模型。这些模型将被传递到服务器端并在服务器端进行聚合,从而得出一个全局模型,并下发给各个参与者。上述过程会迭代直到全局模型收敛。参与者的数量和参与者数据的质量都会显著影响最终模型的性能。参与者会因为以下原因不愿参与联邦学习。首先,参与联邦学习会给参与者带来巨大的计算和通信开销,特别是当这些是像手机这样的低端移动设备时。其次,尽管联邦学习可以保证参与者训练数据的私密性,但本地局部模型也可能被用来推断他们的本地数据,威胁到参与者的隐私。因此,设计一种激励机制进行公平的贡献评估以及酬劳分配来吸引参与者进行训练是非常重要的。本研究提出了一种激励机制方法,该方法考虑以下挑战因素:
首先,计算夏普利值的时间复杂度是参与者数目的指数级别。在跨设备联邦学习中会带来巨大的计算开销。第二,不可或缺的参与者可能会被错误地分配到负的夏普利值,特别是在数据非独立同分布的情况下。这是因为直接使用损失函数或准确度作为特征函数不满足作为必要条件的超可加性。第三,不能适应跨设备联邦学习每轮训练中参与者的动态变化。现有的方法要求参与者自始至终参与训练且不能及时得到他们的酬劳,不完全适用于跨设备联邦学习。
基于上述分析,本研究提出一种基于合作夏普利值的联邦学习激励机制方法,用于贡献评估和酬劳分配。
在这项研究中,我们将联邦学习视为多次单阶段博弈,以充分支持参与者的动态加入和退出,并提出了基于夏普利值的公平高效的贡献评估机制。其基本思想是,参与者的贡献应按迭代进行评估,而不受参与顺序的影响。换句话说,在不同的迭代中,与同一组参与者一起更新全局模型的参与者具有完全相同的贡献。
同时本研究从合作夏普利值入手。这种方法不评估单个参与者对全局模型的影响,而是计算该参与者和所有其他参与者群体合作产生的平均收益。因此,可以消除非独立同分布数据造成的不合理负夏普利值。
本研究证明具有相同数据分布的参与者在策略上是等价的。这意味着具有相同数量等价参与者的组合也是等价的,因此在合作夏普利值中只需考虑一次。为了表示参与者的数据分布,我们使用了局部训练的梯度,并使用二分K-means聚类方法将参与者分为若干组。我们评估的是参与者组的合作夏普利值,而不是单个参与者的合作夏普利值,这就将计算成本从指数级降低到了多项式级。
表1实验结果表明,与两种最先进的近似方法相比(截断蒙特卡洛采样TMC,组测试GT),本研究方法实现了高达25倍的提速,并将误差降低了三个数量级(余弦距离CD,欧几里得距离ED和最大距离MD)。
表格 1不同算法的近似误差和时间开销

研究工作发表在计算机学会推荐A类会议IEEE International Conference on Computer Communications(INFOCOM 2024)上。